Lv.0 词法分析器
我们假设你已经对 Lisp 有了基本的了解。如果没有,请读一下 前置知识 中的内容。
为了减少大家的工作量,我们提供了 脚手架。所谓脚手架,也就是代码框架,或者说代码模板之类的。我们提供了针对主流操作系统、主流 IDE 以及 CMake/Xmake 等构建工具的脚手架生成。请前往 这个页面,按照个人实际和意愿生成并下载脚手架代码。
你下载后会得到一个压缩包,解压后就可以看到这些文件:
README.md:脚手架使用说明文件,必读。mini-lisp.sln或xmake.lua或CMakeLists.txt:这是定义项目相关参数用的,一般情况下不用手动编辑。*.cpp*.h我们提供的部分代码。rjsj_test.hpp是我们提供的“测试框架”,在阶段性检查时使用。- 以及一系列其它配置文件。
根据 README.md 的提示完成 IDE、构建工具等开发环境的配置后,你应该能正常运行这个项目了。它的运行效果是:
>>> (+ 1 2) ; 你在 >>> 后面输入了 (+ 1 2)
(LEFT_PAREN)
(IDENTIFIER +)
(NUMERIC_LITERAL 1.000000)
(NUMERIC_LITERAL 2.000000)
(RIGHT_PAREN)
>>>
TIP
令输入 EOF 以结束程序。在 Windows 上,按 Ctrl+Z 后按回车;在 macOS 上,按 Ctrl+D。
目前提供给你的这份代码就是一个简单的 Mini-Lisp 词法分析器(Tokenizer)。所谓词法分析,就是将一个字符串,分割为若干个小单元;比如将 (+ 1 2) 分割成 ( + 1 2 ) 这五个单元。这样的单元称为 词法标记(Token)。
在 Mini-Lisp 的标准规范中,一共有如下几种词法标记;它们定义在 token.h 的枚举 TokenType 中:
enum class TokenType {
LEFT_PAREN, // 左括号 (
RIGHT_PAREN, // 右括号 )
QUOTE, // 单引号 '
QUASIQUOTE, // 反引号 `
UNQUOTE, // 逗号 ,
DOT, // 点 .
BOOLEAN_LITERAL, // 布尔字面量 #f 或 #t
NUMERIC_LITERAL, // 数型字面量如 42
STRING_LITERAL, // 字符串字面量如 "Hello"
IDENTIFIER, // 标识符(变量名)如 +
};
WARNING
在 Mini-Lisp 规范中,点(DOT .)不是特殊的词法标记,而是标识符的一种。我们为了简化后续讨论,使用了目前的这种分类。
其中反引号和逗号在入门教程中没有提及,也不是重点,目前可以跳过。其它的词法标记我们或多或少都能理解;比如 #t 就代表一个含义为真值的布尔值等等。
总之,我们提供了一个 Tokenizer 类,它的静态方法 Tokenizer::tokenize 接受一个字符串作为待分析的文本,返回一个 std::deque<TokenPtr>,即解析好的词法标记序列。
class Tokenizer {
public:
static std::deque<TokenPtr> tokenize(const std::string& input);
};
这里遇到了一个类型 TokenPtr。它是 std::unique_ptr<Token> 的别名。而 Token 则是一个多态类型,它拥有如 BooleanLiteralToken、StringLiteralToken 等子类。所有的 Token 都实现了 toString 方法,用来输出观察。
任务 0.1 建立 Github 仓库
为了方便项目管理与提交,你需要将项目文件利用 Github 管理,请按照以下顺序操作。
登录 Github 后,在右上角点击"头像 -> Your repositories",进入仓库管理页面后,点击右上角的 "New" 按钮,进入仓库新建页面。
在该页面为你的仓库输入仓库名,并请务必将仓库权限设置为 private。随后点击 "Create repository" 后即可创建自己的仓库。
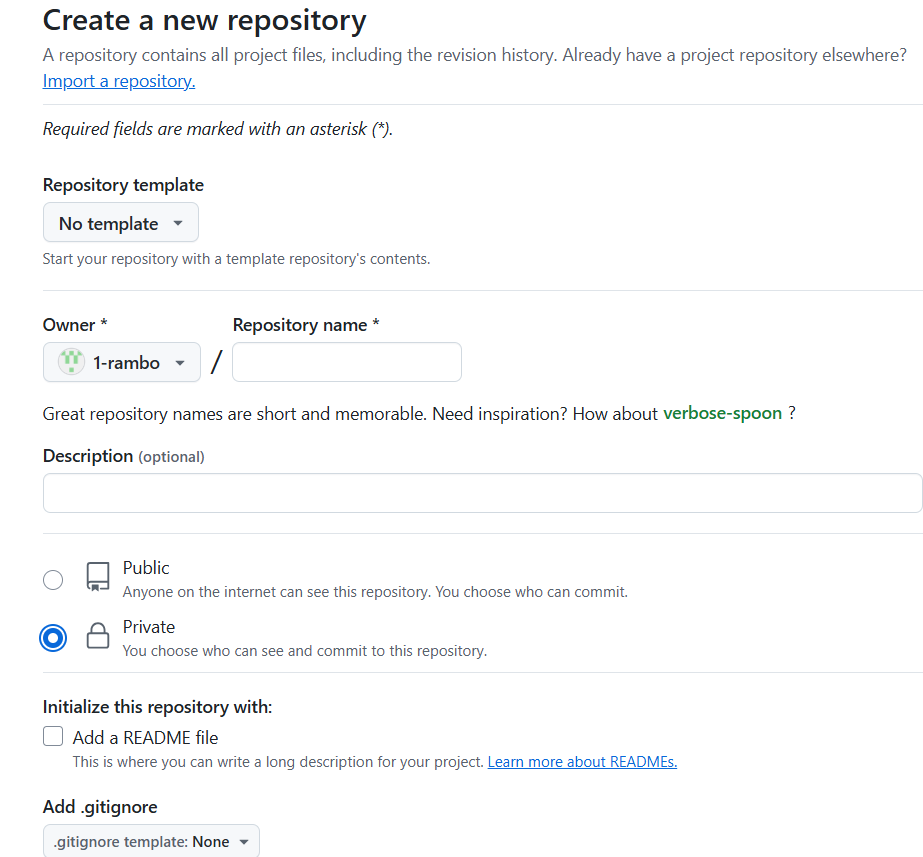
在弹出的新页面中如下图所示,点击 "SSH",并点击右侧按钮复制你的仓库地址(形如
git@github.com:<your-github-username>/<your-github-repo-name>.git)。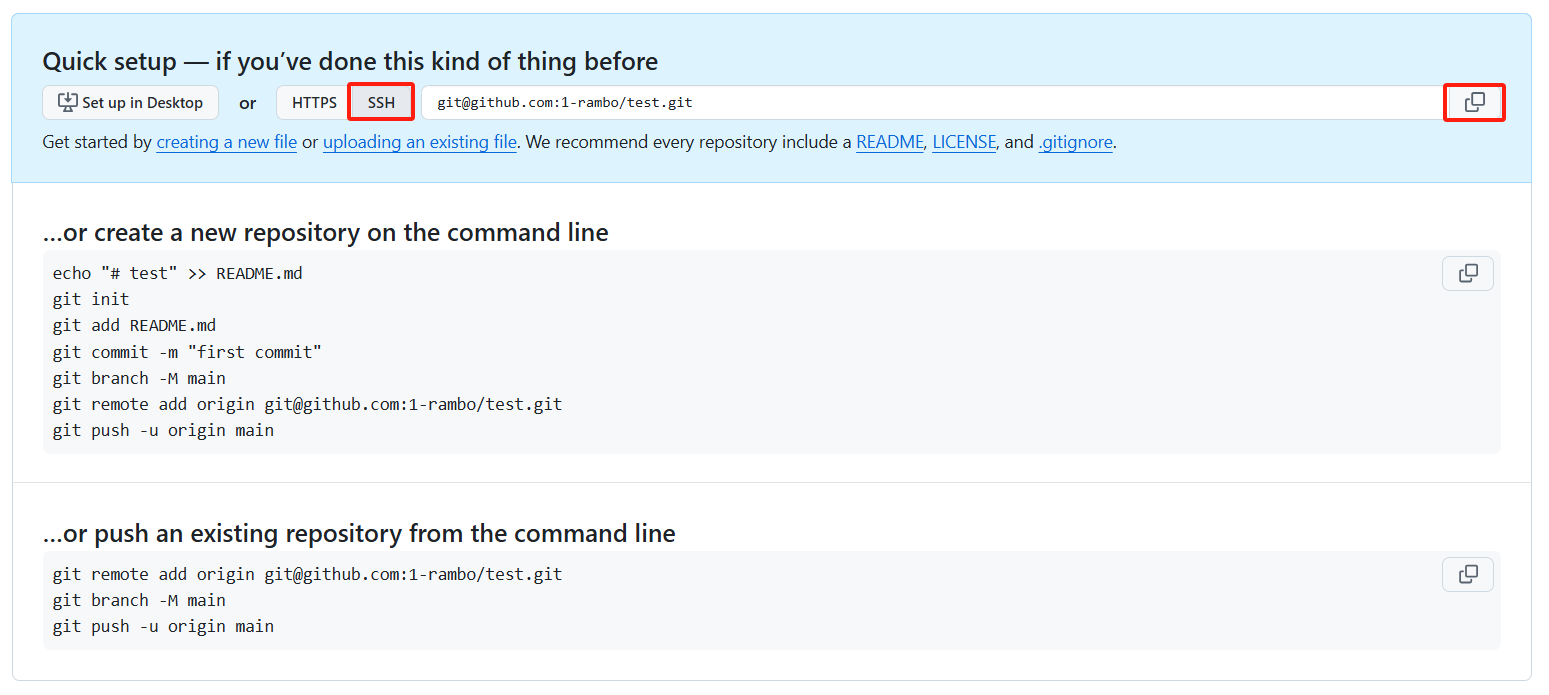
检查本机的 ssh 配置,在终端中运行以下命令:
cd ~/.ssh
ls
查看该目录下是否有 id_rsa 与 id_rsa.pub 文件,如果存在,说明你的电脑已经配置好,可以直接进入第六步。
- 如果你的
~/.ssh目录下没有这些文件,那么在该目录下运行以下命令:
ssh-keygen -t rsa -C "your-email@xxx.com" # 其中将 "your-email@xxx.com" 替换为你用于注册 Github 所用的邮箱地址
# 此后默认回车即可
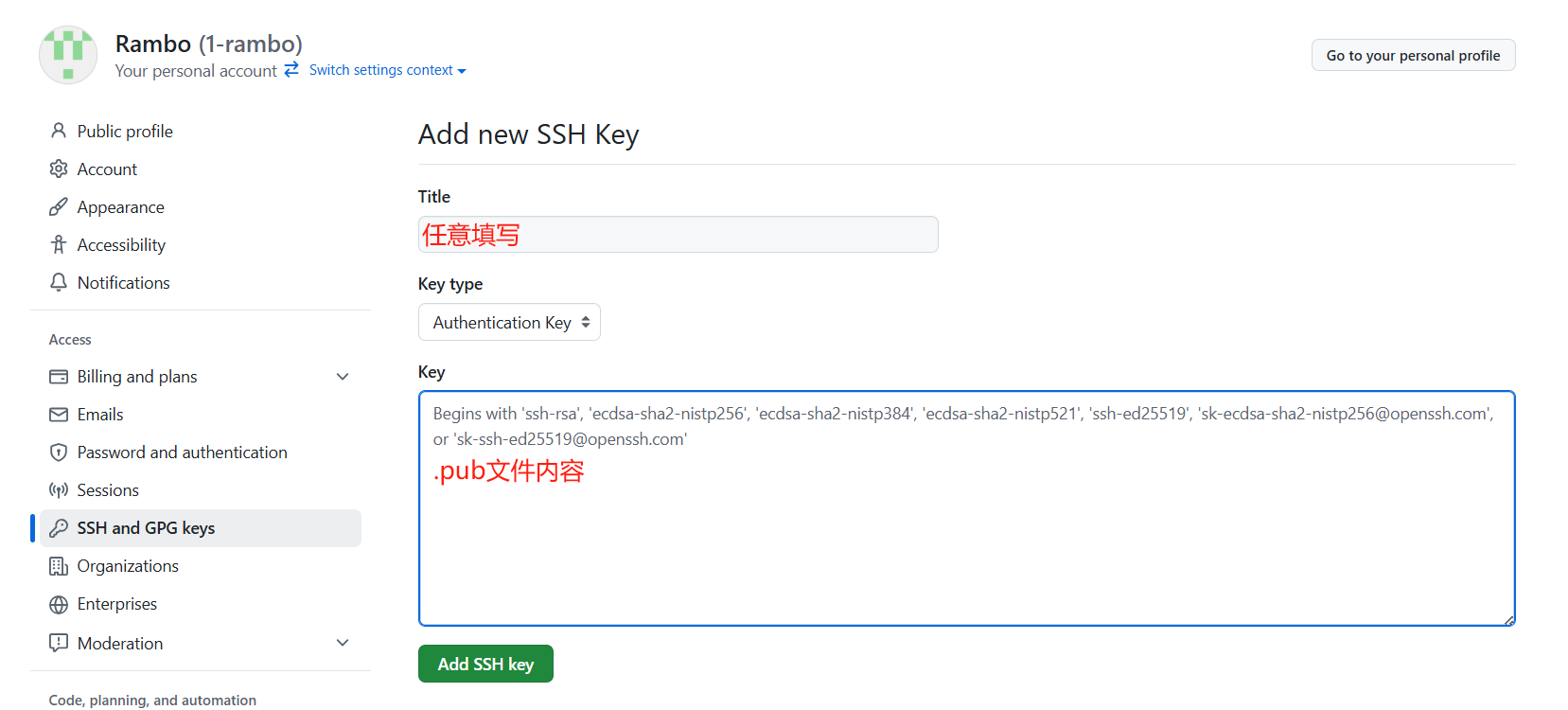
- 生成后,点击 Github 右上角的"头像 -> Settings",点击左侧的 "SSH and GPG keys",随后点击右上角的 "New SSH Key",按照下图所示,在 "key" 栏将你上一步生成的 id_rsa.pub 文件内容复制进来,注意不要复制成 id_rsa 文件。随后点击 "Add SSH Key" 完成配置工作。
 你可以通过如下命令检查你的配置是否正确:
你可以通过如下命令检查你的配置是否正确:
ssh -T git@github.com
如果出现 "Hi" 开头的文字,表明配置正确。
- 按照中作业文档的指示配置好 git 后,在终端中进入解压后的脚手架目录,运行以下命令:
git init # 初始化 git 仓库
git add . # 添加所有文件到 git 仓库
git commit -m "init" # 提交代码
git branch -M main # 将当前分支重命名为 main, 如果确定 git 的默认分支是 main 可以不执行这条命令
git remote add origin <your-github-repo-url> # 添加远程仓库地址,将 <your-github-repo-url> 替换为你在第三步中复制的地址
git push -u origin main # 将代码推送到远程仓库
之后就可以像在中作业中那样正常使用 git 了。
任务 0.2 阅读代码
接下来,请你阅读 token.h、tokenizer.h 和 main.cpp,搞清楚目前程序的大概结构。如果你感兴趣的话,也可以读一读 tokenizer.cpp 或者其它文件,彻底理解目前程序的工作原理。
试回答以下问题:
- 为什么
Tokenizer::tokenize接受的形参类型是const std::string&而不是std::string?可不可以用std::string&? - 为什么使用
TokenPtr,也即std::unique_ptr<Token>?如果改用Token*,会有什么影响? - main 函数中
std::cout << *token是如何实现的? - 当词法分析出现错误时,程序是如何进行错误处理的?
- * 使用
std::deque<TokenPtr>相比std::vector<TokenPtr>的好处是什么?
在你的工作文件夹下新建 lv0-answer.txt,将以上问题你的解答与思考写下。
作为 Level 0,本部分没有代码编写的工作。但是如果你认为你已经理解了目前的程序的话,那么这是一个非常好的信号——让我们开始敲代码吧!
阶段性检查
在 2026 年 5 月 3 日 23:59:59 前在教学网 大作业 / Lv.0 检查 处,提交 lv0-answer.txt。